Just-in-Time Compilation Transform
This tutorial demonstrates the performance benefits of JAX's just-in-time (JIT) compilation for finite element solvers in FEAX. JIT compilation dramatically accelerates repeated solver calls by eliminating Python overhead and enabling XLA optimizations.
Overview
JAX's jax.jit compiles functions to optimized machine code. For FEA solvers this provides:
- Significant speedup for repeated solver calls
- One-time compilation overhead on the first call
- Cached compiled code for subsequent calls with the same structure
Problem Setup
We use the same cantilever beam problem from the Linear Elasticity tutorial:
import feax as fe
import jax
import jax.numpy as np
import time
E = 70e3
nu = 0.3
traction = 1.
tol = 1e-5
L, W, H = 100, 10, 10
mesh = fe.mesh.box_mesh((L, W, H), mesh_size=1)
left = lambda point: np.isclose(point[0], 0., tol)
right = lambda point: np.isclose(point[0], L, tol)
class LinearElasticity(fe.problem.Problem):
def get_tensor_map(self):
def stress(u_grad, *args):
mu = E / (2. * (1. + nu))
lmbda = E * nu / ((1 + nu) * (1 - 2 * nu))
epsilon = 0.5 * (u_grad + u_grad.T)
return lmbda * np.trace(epsilon) * np.eye(self.dim) + 2 * mu * epsilon
return stress
def get_surface_maps(self):
def surface_map(u, x, traction_mag):
return np.array([0., 0., traction_mag])
return [surface_map]
problem = LinearElasticity(mesh, vec=3, dim=3, location_fns=[right])
bc_config = fe.DCboundary.DirichletBCConfig([
fe.DCboundary.DirichletBCSpec(location=left, component="all", value=0.)
])
bc = bc_config.create_bc(problem)
Creating JIT and Non-JIT Solvers
traction_array = fe.TracedParams.create_uniform_surface_var(problem, traction)
traced_params = fe.TracedParams(volume_vars=(), surface_vars=[(traction_array,)])
solver_option = fe.DirectSolverOptions()
solver_no_jit = fe.create_solver(problem, bc, solver_option, linear=True, traced_params=traced_params)
solver_jit = jax.jit(fe.create_solver(problem, bc, solver_option, linear=True, traced_params=traced_params))
initial = fe.zero_like_initial_guess(problem, bc)
jax.jit wraps the solver into a compiled function. Compilation happens on the first call and is cached for subsequent calls.
Benchmarking
# No JIT
start = time.perf_counter()
sol_no_jit = solver_no_jit(traced_params, initial).block_until_ready()
time_no_jit = time.perf_counter() - start
# JIT — first call (includes compilation)
start = time.perf_counter()
sol_jit_first = solver_jit(traced_params, initial).block_until_ready()
time_jit_with_compile = time.perf_counter() - start
# JIT — second call (compiled, fast)
start = time.perf_counter()
sol_jit_second = solver_jit(traced_params, initial).block_until_ready()
time_jit_compiled = time.perf_counter() - start
compile_overhead = time_jit_with_compile - time_jit_compiled
speedup = time_no_jit / time_jit_compiled
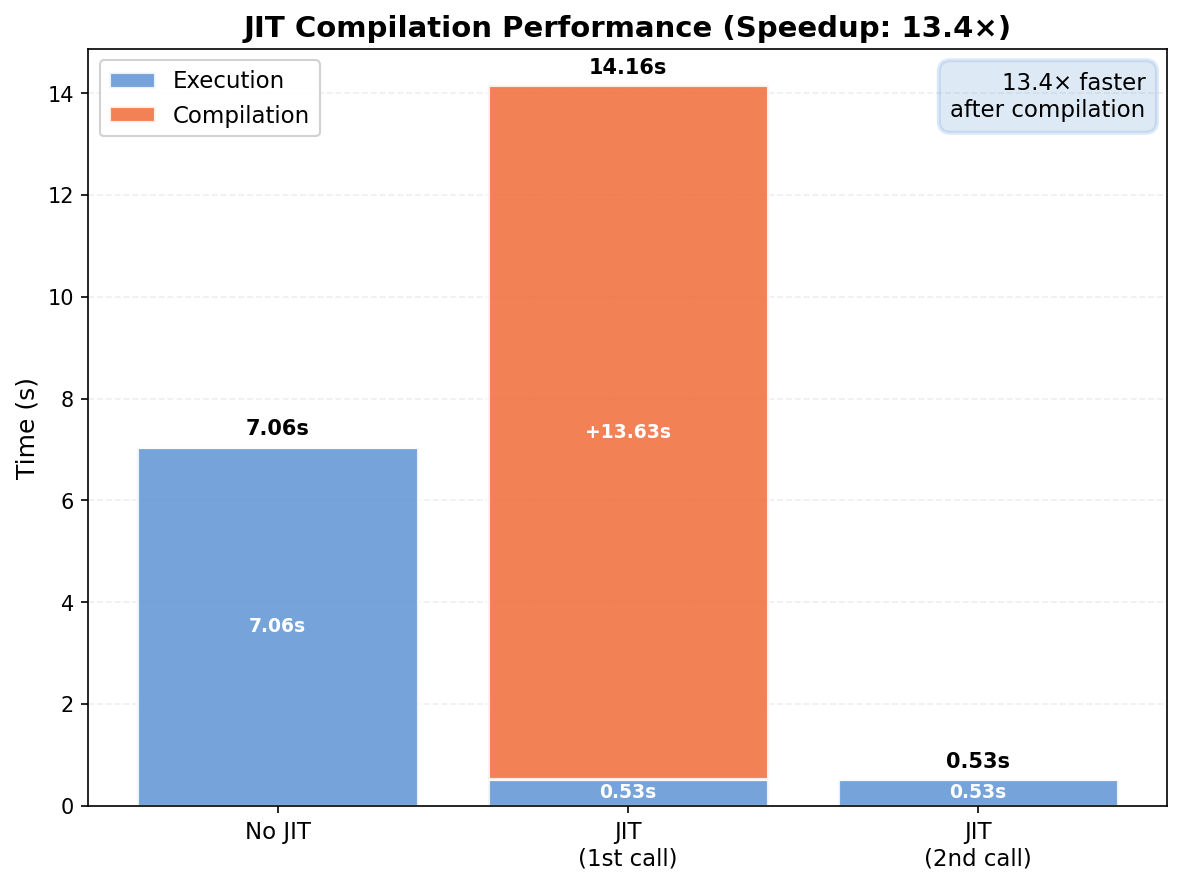
print(f"No JIT: {time_no_jit:.3f}s | JIT (1st): {time_jit_with_compile:.3f}s | JIT (2nd): {time_jit_compiled:.3f}s | Speedup: {speedup:.2f}x")
Use .block_until_ready() when benchmarking to account for JAX's asynchronous execution.
Visualization
import matplotlib.pyplot as plt
jax_blue = '#5E94D4'
jax_orange = '#F26B38'
fig, ax = plt.subplots(figsize=(8, 6))
categories = ['No JIT', 'JIT\n(1st call)', 'JIT\n(2nd call)']
execution_times = [time_no_jit, time_jit_compiled, time_jit_compiled]
compile_times = [0, compile_overhead, 0]
x_pos = np.arange(len(categories))
ax.bar(x_pos, execution_times, color=jax_blue, alpha=0.85, label='Execution', edgecolor='white', linewidth=1.5)
ax.bar(x_pos, compile_times, color=jax_orange, alpha=0.85, label='Compilation', edgecolor='white', linewidth=1.5,
bottom=execution_times)
for i, (exec_t, comp_t) in enumerate(zip(execution_times, compile_times)):
total = exec_t + comp_t
ax.text(i, total + 0.15, f'{total:.2f}s', ha='center', va='bottom', fontsize=10, fontweight='bold')
if exec_t > 0.5:
ax.text(i, exec_t / 2, f'{exec_t:.2f}s', ha='center', va='center', fontsize=9, color='white', fontweight='bold')
if comp_t > 0.5:
ax.text(i, exec_t + comp_t / 2, f'+{comp_t:.2f}s', ha='center', va='center', fontsize=9, color='white', fontweight='bold')
ax.text(0.98, 0.97, f'{speedup:.1f}× faster\nafter compilation',
transform=ax.transAxes, ha='right', va='top', fontsize=11,
bbox=dict(boxstyle='round,pad=0.5', facecolor=jax_blue, alpha=0.2, edgecolor=jax_blue, linewidth=2))
ax.set_ylabel('Time (s)', fontsize=12)
ax.set_title(f'JIT Compilation Performance (Speedup: {speedup:.1f}×)', fontsize=14, fontweight='bold')
ax.set_xticks(x_pos)
ax.set_xticklabels(categories, fontsize=11)
ax.legend(fontsize=11, framealpha=0.9)
ax.grid(True, alpha=0.2, axis='y', linestyle='--')
ax.set_axisbelow(True)
plt.tight_layout()
plt.savefig('jit_comparison.png', dpi=150, bbox_inches='tight')
Save Solution
import os
sol_unflat = problem.unflatten_fn_sol_list(sol_jit_second)
displacement = sol_unflat[0]
data_dir = os.path.join(os.path.dirname(__file__), 'data')
os.makedirs(os.path.join(data_dir, 'vtk'), exist_ok=True)
fe.utils.save_sol(mesh=mesh, sol_file=os.path.join(data_dir, 'vtk/u_jit.vtu'),
point_infos=[("displacement", displacement)])
Key Takeaways
- Significant speedup for repeated solver calls via XLA compilation
- One-time compilation overhead on the first call — quickly amortized
- Essential for optimization and parameter studies
- Combine with
jax.vmapandjax.gradfor differentiable physics workflows - Use
.block_until_ready()when benchmarking asynchronous JAX computations
Further Reading
- Vectorization Transform — combine JIT with
jax.vmap - Nonlinear Hyperelasticity — JIT with Newton iterations